
Given the exponential growth in data complexity, how can you, the risk manager, quickly determine the most salient economic factors to include in calculating a bank’s risk exposure?
Nowadays, modelling risk is all about “speed, accuracy, and defensibility,” said Patrick Rogers, Head of Marketing at the software company Ayasdi. Risk models must be developed “in a relatively short time window and must be statistically valid.”
Since risk models must be defensible to business owners and industry regulators, and simple to explain, the ordinary “black box” machine learning would fall flat, Rogers said. He was the second of three panellists at the October 27, 2015, webinar on Effective Risk Models Using Machine Intelligence sponsored by the Global Association of Risk Professionals.

When modelling reality, complexity is the challenge that must be overcome. Given a set of 2,700 economic variables, “the number of possible models created from the dataset exceeds two trillion,” he said. In the near future, year over year, the amount of available data is expected to grow forty percent. The number of possible models created from that would exceed eight trillion, he noted. “We can no longer brute-force our way out of this.”
Previous methods required humans to apply “conventional machine methods” in what Rogers called a “guess and check” approach, which was “extremely iterative and time-consuming” and could often lead to over-fitted models. Oftentimes, the regulator was unconvinced about the goodness of the model.
A proper design of man-machine workflow would combine machine intelligence with business intuition. Machine learning would optimize quantitative aspects, but a human expert would select the inputs and evaluate the ultimate output.
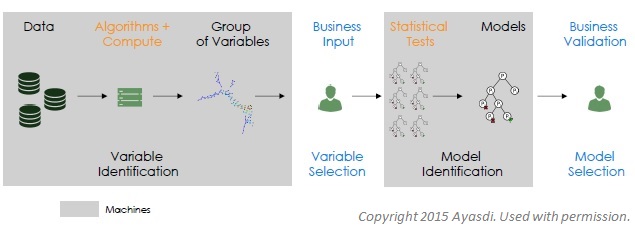
In summary, Rogers said the best approach would “rapidly identify highly correlated variables, incorporate business logic, and create simple, accurate, defensible models.” All would be subject to “transparent review.” ª
Click here to read about the first presentation.
Click here to read about the third presentation.
Click here to download the Ayasdi risk modeling white paper.