“People are more likely to believe something that comes as data,” said Joe Pimbley, Principal, Maxwell Consulting, “but you shouldn’t necessarily believe the data.” Pimbley, a lead investigator for the examiner appointed by the Lehman Brothers bankruptcy court, addressed financial risk management professionals at a GARP webinar on August 6, 2013. [Ed. Note Click here to read Joe Pimbley – “Why Lehman Brothers Failed When It Did” on Stories.Finance.]
Pimbley said that model builders must always look at data with the eyes of a skeptic. With a PhD in physics he is conversant with models devised to predict the “real world” and is aware of the false security that data-based models can provide. He cited as an example the default probability of covered bonds in Europe. If there has never been a default in one hundred years, Pimbley said the modeller must ask, “Is it true? Even if true, is ‘zero default’ helpful?” The economic and regulatory environment in which those data points were gathered will have changed greatly over that century.
“It’s necessary to understand what history tells us … but that’s not enough,” he said, to know the details of trading positions and strategies. He contrasted three data sets (the 10-Year US treasuries, the iTraxx credit default swaps index, and the Spanish GDP) and the models that could be built from them.
The 10-Year US treasuries was a “gold standard” of data, with thousands of points over several decades whereas the Spanish GDP data set was relatively sparse, with its once-a-year data points. The iTraxx set, with 1800 points, was of intermediate size and quality.
Pimbley explained the models as he went along. Models of stochastic processes typically begin with normal and log-normal forms because the math is straightforward and it’s consistent with market efficiency. He urged listeners not to get too fixated on the Central Limit Theorem which is often presented in an “obscure and abstract” fashion.
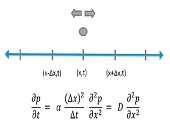
There is a probability a particle can go in either direction, and from the partial differential equation for diffusion, he showed how one could solve for Brownian motion and get a normal distribution. (See figure.)

Pimbley pointed out one common slip-up in looking at the distribution of US Treasury yields. “Don’t simply take the standard deviation of yields,” he advised. “It’s the standard deviation of the difference between sequential yields that you need to look at.”
Auto-regression is the prediction of a variable at a given time from prior values of that variable. “But what is the concept behind auto-regression?” he asked, noting that engineers call it a “black box model” since it has a smoke-and-mirrors quality to it. Although users seldom program models from scratch nowadays, Pimbley stressed that a user must “be aware of software nuances, especially when working with a small number of points.”
There is little guidance on what to choose for p, the order of the auto-regressive model. Pimbley gave two examples. For the US Treasuries dataset, he said the p=1 choice showed log-normal was a good assumption but the p=2 case was even better. The root mean square error of the fit (RMSE) was the same “but correlation of errors is closer to zero for p=2.” He observed the same result for the 1800-point iTraxx dataset.
Pimbley was unaware of a stochastic model for p=2. He suggested the problem be thought of as a Riemann sum, and with this he obtained the mean-reversion result. However, he was reluctant to adopt the mean-reversion model . “The impact on forward-projected probability distributions is huge for tail events at long times—which is further reason for caution,” he said.
The final data set he looked at was the Spanish GDP. “Sovereign economic data is not high on the trust scale,” thus, he suggested ten percent uncertainty for each data point based on recommendations from Grant’s Interest Rate Observer. The world has seen with Argentina, Greece, China, and other cases that the providers of sovereign data do not have a superior track record of veracity. Besides, “how do we use historical data over a period of no default? Do we use or ignore the pre-euro period?” he challenged the audience.
“Data review is best at disproving what we think we know,” said Pimbley. The role of data often lies in refuting models and concepts.
Although data cannot be fully trusted, prediction and model-building are still important activities. A model can be thrown away, but modelling itself should not be thrown away. “Apply the model as if you think it’s true,” he said. “See the distribution of results” then remove certain assumptions and see what happens.
And then there are cases of market irrationality. He advised young risk managers (and traders and regulators and central bankers) to read and know the history of their focus areas. “If you’re a bank risk manager, read the history of bank practices and failures of the past few hundred years,” he said. Just as we study historical data with quantitative methods, we should also be students of history in a qualitative vein, too. To paraphrase Mark Twain: “history does not repeat itself, but it often rhymes.”ª
The webinar presentation slides can be found at: http://event.on24.com/r.htm?e=654546&s=1&k=6C25231B4CE090CE80B7F7694C79D7F2
Added March 3, 2023. Click here to read Joe Pimbley – “Why Lehman Brothers Failed When It Did” on Stories.Finance.